13 min to read
보통 정렬 알고리즘
기본 정렬보다 조금 나은 보통 정렬 알고리즘에 대해 알아봅니다.
기본 정렬 알고리즘은 시간 복잡도가 O(N^2) 이기 때문에 실무에서는 잘 사용하지 않습니다.
그래서 구현하는 방법이 조금 어려울지 언정, 실무에서 많이 쓰이는 보통 정렬 알고리즘에 대해 알아 보겠습니다.
이번 장에서는 시간 복잡도가 O(N log N) 에 해당 되는 정렬 알고리즘에 대해 포스팅 하겠습니다.
Merge Sort
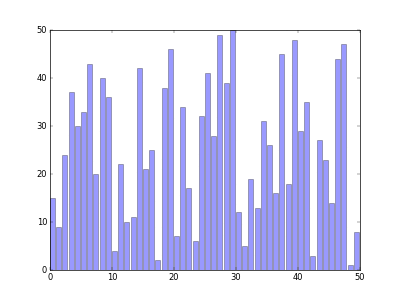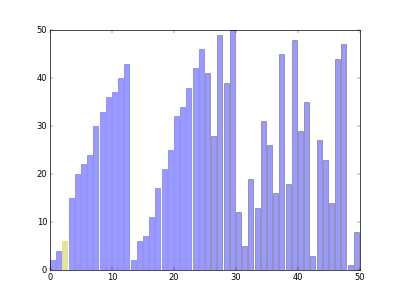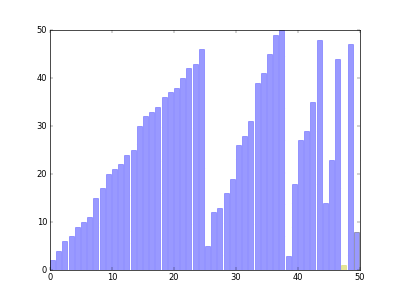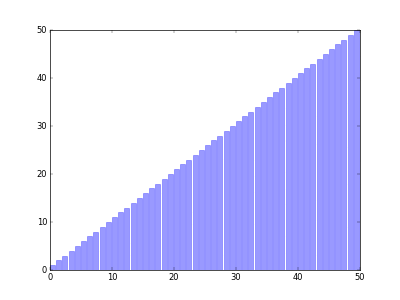
- 분할 정복(Divide Conquer) 개념을 적용 시킨 정렬 알고리즘.
- 이분할(Binary) 작업이 log(2) N 일어나기 때문에 분할에 대한 시간 복잡도는 O(log N).
- 분할 된 배열에 대하여 값들을 채워서 정렬하는 시간 복잡도는 O(N).
- 총 시간 복잡도는 O(N log N). 그렇지만 임시 저장 공간이 필요하기 때문에 공간 복잡도는 O(N).
- 정렬된 값들을 유지하는 안정 정렬(Stable Sort) 에 해당.
소스 코드는 아래와 같습니다.
import java.util.Arrays;
public class MergeSort {
static void merge(int[] arr, int start, int mid, int end){
int len = end - start + 1;
int[] tmp = new int[len];
int i = 0;
int idx1 = start;
int idx2 = mid + 1;
// 일단 두 배열에 있는 값을 비교하여 작은 것을 넣어줍니다.
while(idx1 <= mid && idx2 <= end){
if(arr[idx1] < arr[idx2])
tmp[i++] = arr[idx1++];
else
tmp[i++] = arr[idx2++];
}
// 나머지 처리(시작 - 중앙 부분)
while(idx1 <= mid)
tmp[i++] = arr[idx1++];
// 나머지 처리(중앙 - 끝 부분)
while(idx2 <= end)
tmp[i++] = arr[idx2++];
// 배열 복사
for(int k = 0; k < len; k++)
arr[start + k] = tmp[k];
}
static void merge_sort(int[] arr, int start, int end){
if(start >= end) return;
int mid = (start + end) / 2;
merge_sort(arr, start, mid);
merge_sort(arr, mid + 1, end);
merge(arr, start, mid, end);
}
public static void main(String[] args){
int[] array = new int[] { 9, 2, 5, 3, 6, 1, 7, 8, 10, 4 };
merge_sort(array, 0, array.length - 1);
System.out.println(Arrays.toString(array));
}
}
Heap Sort
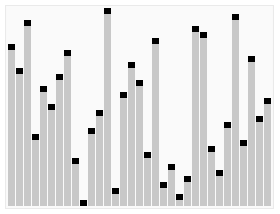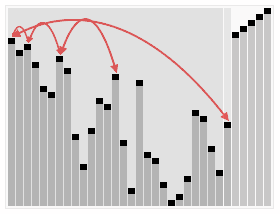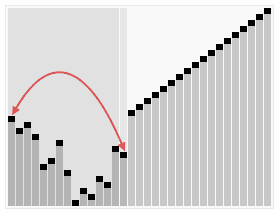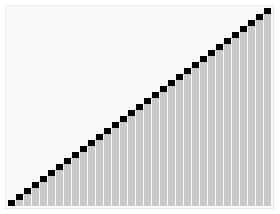
- 최대 힙(Max Heap), 최소 힙(Min Heap) 을 사용하여 맨 위의 값들을 마지막 인덱스로 보내고 정리(
heapify) 하는 정렬 방식. - Heap 을 정리하는 횟수는 log(2) N 번 으로
heapify함수의 시간 복잡도는 O(log N). - 각 배열의 요소를 마지막 인덱스로 보내야 되기 때문에 총합 시간 복잡도는 O(N log N).
- Heap 자료구조는 최댓값 혹은 최솟값 등 정렬 이후 양 끝에 있는 자료들만 가져올 때 효율적.
소스 코드는 아래와 같습니다.
import java.util.Arrays;
public class HeapSort {
static void swap(int[] arr, int x, int y){
int tmp = arr[x];
arr[x] = arr[y];
arr[y] = tmp;
}
// build_heap 메소드는 중앙 인덱스부터 0 까지 Heap 자료구조로
static void build_heap(int[] arr){
int end = arr.length - 1;
for(int k = (end - 1) / 2; k >= 0; k--)
heapify(arr, k, end);
}
// heapify 메소드는 배열을 Heap 자료구조로 정리하기 위한 용도입니다.
static void heapify(int[] arr, int k, int end){
int left = 2 * k + 1, right = 2 * k + 2;
int smaller;
if(right <= end)
smaller = (arr[left] > arr[right]) ? left : right;
else if(left <= end) smaller = left;
else return;
if(arr[smaller] > arr[k]){
swap(arr, smaller, k);
heapify(arr, smaller, end);
}
}
static void heap_sort(int[] arr){
build_heap(arr);
for(int end = arr.length - 1; end >= 1; end--) {
swap(arr, 0, end);
heapify(arr, 0, end - 1);
}
}
public static void main(String[] args){
int[] array = new int[] { 9, 2, 5, 3, 6, 1, 7, 8, 10, 4 };
heap_sort(array);
System.out.println(Arrays.toString(array));
}
}
Quick Sort
- 시간 복잡도가 O(N log N) 인 정렬 알고리즘 중 보편적 으로 사용되는 알고리즘.
- 병합 정렬(Merge Sort) 와 마찬가지로 분할 정복을 적용한 알고리즘.
- 기준(
pivot) 인덱스의 값 보다 작으면 왼쪽, 크면 오른쪽으로 보내는 알고리즘. pivot인덱스의 값은 아무 곳에서 시작됨.
(대부분 끝탱이를 사용. 웬만하면 중앙 인덱스를 사용하는 것이 좋긴 함.)- 시간 복잡도는 분할 횟수인 O(log N) X 기준 인덱스 찾는 시간 복잡도 O(N).
전부 작동하는 시간 복잡도는 O(N log N). - 그렇지만
pivot인덱스의 값이 평균 값이 아니라 양 끝에 해당된 값이면 시간 복잡도가 O(N^2) 가 나오는 불상사가 발생함. - 참고로 퀵 정렬을 구상한 컴퓨터 과학자는 아직도 건재하신 건 안 비밀.
소스 코드는 아래와 같습니다.
import java.util.Arrays;
public class QuickSort {
static void swap(int[] arr, int a, int b){
int tmp = arr[a];
arr[a] = arr[b];
arr[b] = tmp;
}
static int partition(int[] arr, int from, int to){
int value = arr[to]; // 기준 값은 끝탱이를 잡아도 큰 상관은 없습니다.
int k = from - 1;
for(int l = from; l <= to - 1; l++)
if(arr[l] < value)
swap(arr, ++k, l);
swap(arr, k + 1, to); // 마지막에 끝탱이를 맨 가운데로 가져옵니다.
return k + 1;
}
static void quick_sort(int[] arr, int start, int end){
if(start >= end) return;
int pivot = partition(arr, start, end);
quick_sort(arr, start, pivot - 1);
quick_sort(arr, pivot + 1, end);
}
public static void main(String[] args){
int[] array = new int[] { 9, 2, 5, 3, 6, 1, 7, 8, 10, 4 };
quick_sort(array, 0, array.length - 1);
System.out.println(Arrays.toString(array));
}
}
3-Way Partition Quick Sort
- 기존 2-분할 Quick Sort 에서 사용된
pivot을 2개로 늘려 3 영역으로 값들을 배치 시키는 방식. - 시간 복잡도는 그대로 O(N log N). 그렇지만 기존 Quick Sort 보다 빠름.
(log(3) N < log(2) N) pivot인덱스의 편향 선택(양쪽 끝 값) 으로 인한 최악의 상황을 어느 정도 해결할 수 있음.- 이후
pivot의 개수가 많아지면 비교 과정에서 시간을 더 잡아 먹기 때문에 비효율적일 것임.
(즉,pivot개수도 정도 껏.)
소스 코드는 아래와 같습니다.
import java.util.Arrays;
public class DualPivotQuickSort {
static class Pair {
int primary;
int secondary;
public Pair(int primary, int secondary){
this.primary = primary;
this.secondary = secondary;
}
}
static void swap(int[] a, int x, int y){
int tmp = a[x];
a[x] = a[y];
a[y] = tmp;
}
static Pair partition(int[] a, int start, int end){
if(a[end - 1] > a[end]) swap(a, end - 1, end);
int v1 = a[end - 1];
int v2 = a[end];
int i1 = start - 1;
int i2 = start - 1;
for(int k = start; k <= end - 2; k++){
if(a[k] < v1) {
swap(a, ++i1, k);
if(i2 < i1) i2 = i1;
else swap(a, ++i2, k);
} else if(a[k] < v2) {
swap(a, ++i2, k);
} else continue;
}
swap(a, ++i1, end - 1);
if(i2 < i1) i2 = i1;
else swap(a, ++i2, end - 1);
swap(a, ++i2, end);
return new Pair(i1, i2);
}
static void three_way_quick_sort(int[] a, int start, int end){
if(start >= end) return;
Pair pivot = partition(a, start, end);
three_way_quick_sort(a, start, pivot.primary - 1);
three_way_quick_sort(a, pivot.primary + 1, pivot.secondary - 1);
three_way_quick_sort(a, pivot.secondary + 1, end);
}
public static void main(String[] args){
int[] array = new int[] { 9, 2, 5, 3, 6, 1, 7, 8, 10, 4, -2, -9, -3, -1, -7, -8, 0, 6 };
three_way_quick_sort(array, 0, array.length - 1);
System.out.println(Arrays.toString(array));
}
}
Reference
정렬 과정을 비교하는 사이트 입니다.
이 사이트를 사용하면 더욱 시각화 된 정렬 과정을 보실 수 있습니다.
https://www.toptal.com/developers/sorting-algorithms

Comments